Cloudera Streaming Analytics – SQL Stream Builder

Cloudera SQL Stream Builder ile Gerçek Zamanlı Veri İşleme
Günümüzün hızla evrilen dijital dünyasında, organizasyonlar sürekli olarak gerçek zamanlı verilere dayalı kararlar almayı hedeflemektedirler. Veri akışlarını yakalama ve işleme yeteneği, endüstriler arasında rekabet avantajını belirleyen bir unsur haline gelmiştir. İşte tam burada Cloudera SQL Stream Builder, gerçek zamanlı veri işleme ve analizine yönelik güçlü bir araç olarak devreye girmektedir.
İçeriğimizin devamında, SSB’nin özelliklerini, mimarisini, yeteneklerini ve veri odaklı bir dönemde organizasyonlara sunabileceği büyük potansiyeli inceledik.
SQL Stream Builder Mimarisi
Cloudera Streaming Analytics, Flink’e ek olarak veri akışlarında SQL yeteneklerinizi kullanarak analiz deneyimi sunmak için SQL Stream Builder ürününü çıkarmıştır.
Gerçek zamanlı akan bir veriye SQL sorgusu atmak mı? İlk başta kulağa garip gelebilir fakat SSB’nin tam olarak yaptığı iş budur. SSB, yazılan SQL komutlarının sürekli olarak çalışmasını sağlamaktadır. Bu işleme Continuous SQL (Sürekli SQL) denir. SSB’de SQL sorgusu yazıp, sorguyu çalıştırdığınızda arka planda otomatik olarak bir Flink jobı oluşmaktadır. Yani aslında her bir SSB sorgusu bir Flink job’ına denk gelmektedir. Bu sayede Flink kullanılarak uzun uzun java kodları yazmak yerine birkaç satır SQL kodu ile veri üzerinde işleme, filtreleme ve dönüşümler yapılabilir.
Veri istenilen forma getirildikten sonra işlenmiş verileri sink ile veritabanlarına gönderilebilir. Sink connector’e ek olarak SSB, elde edilen sonuçları, REST protokolü üzerinden kalıcı bir görünüme dönüştürme yeteneğine sahiptir. Böylece diğer uygulamalar REST API kullanarak verilere erişebilir. Bu mimariye SSB’de Materialized Views adı verilir. Materialized Views, SQL Stream Builder hizmetinde yerleşiktir ve herhangi bir yapılandırma veya bakım gerektirmez. Süreci gösteren mimari çizim aşağıdaki gibi ifade edilebilir.
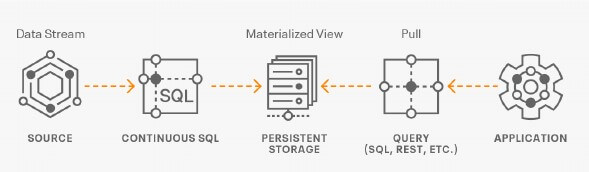
Veri tabanlarında verilerin değişimini anlık olarak yakalamanızı sağlayan en sık kullanılan CDC (Change Data Capture) araçlarının arasında bulunan Debezium, SSB’nin içinde bir connector olarak yer alır. Debezium connector u ile kaynak olarak PostgreSQL, Oracle, MySQL, Db2 ve SQL Server ortamlarını kullanarak CDC (Change Data Capture) yapabilirsiniz.
SQL Stream Builder Kullanım Avantajları
- SQL Kullanarak Veri İşleme: Real-time akan veriyi SQL sorguları kullanarak filtreleme ve dönüştürme imkanı sunar.
- Hedef Kaynaklara Yazma İşlemi: Akan verileri Kafka, JDBC, Hive, Kudu gibi kaynaklara yazma imkanı sunar.
- REST API: Akan verileri REST protokolü üzerinden kalıcı bir görünüme dönüştürür ve diğer uygulamaların REST API kullanarak veriye erişmesini sağlar.
- Kullanışlı Arayüz: Bir jobı çalıştırdıktan sonra akan verilerin çıktıları incelenebilir, aynı ekran üzerinden verileri başka kaynaklara gönderilebilir ve log çıktıları incelenebilir.
SSB Arayüz Tanıtımı
SQL Stream Builder (SSB) servisini ekledikten sonra Cloudera Manager üzerinden SSB servisini seçip web arayüzüne erişim sağlanır. SSB arayüzü aşağıdaki gibi görünmektedir.
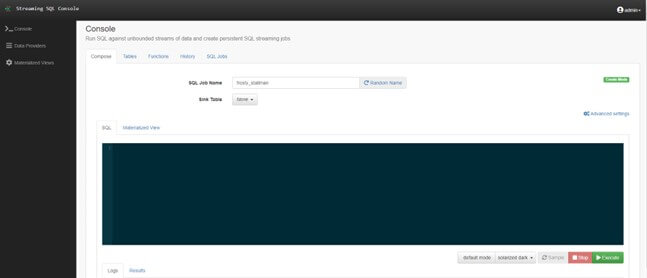
SSB ekranına giriş yapıldığında ilk olarak Console ekranı açılır. Bu ekranın içinde, Compose bölümünde SQL kodları yazabilir ve çalıştırabilirsiniz. Ayrıca, Kafka ve flink ddl tablolarını oluşturabileceğiniz Tables bölümü, javascript kullanarak fonksiyonlar oluşturabileceğiniz Function bölümü, önceden yazdığınız SQL kodlarını inceleyebileceğiniz History bölümü ve aktif olarak çalışan jobları listeleyebileceğiniz SQL Jobs bölümü bulunmaktadır.
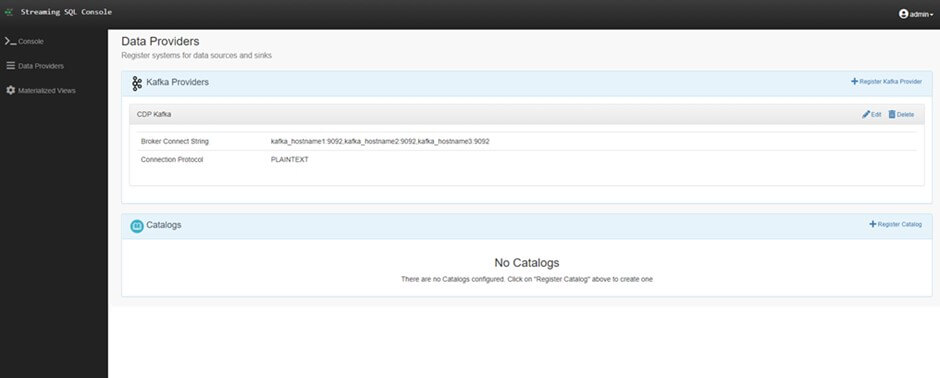
SSB ekranının sol menüsündeki “Data Providers” bölümü, veri kaynaklarını eklememize ve yönetmemize olanak tanır. Bu bölümde “Kafka Providers” ve “Catalogs” olmak üzere iki seçenek bulunur. Yukarıdaki şekilde “Kafka Providers” bölümünde görüldüğü gibi Cloudera’da bulunan Kafka cluster bilgileri SSB kurulurken Cloudera Manager tarafından otomatik olarak eklenir. Cloudera’da kurulu olan Kafka clusterının yanı sıra external Kafka cluster bilgileri de SSB’ye eklenebilir.
Catalogs bölümünde ise Schema Registry, Kudu, Hive ve custom seçeneklerle Cloudera’da bulunan mevcut tabloları SSB platformuna entegre edebilirsiniz. Bu sayede SQL Console ekranında yazdığınız jobların çıktılarını “Sink Table” seçeneği ile Hive veya Kudu tablolarına gönderebilirsiniz.
Örnek olarak Cloudera’da bulunan Hive tablolarını Catalogs’a ekleyelim. “Register Catalog” butonuna tıklandığı zaman Add Catalog ekranı karşımıza gelmektedir.
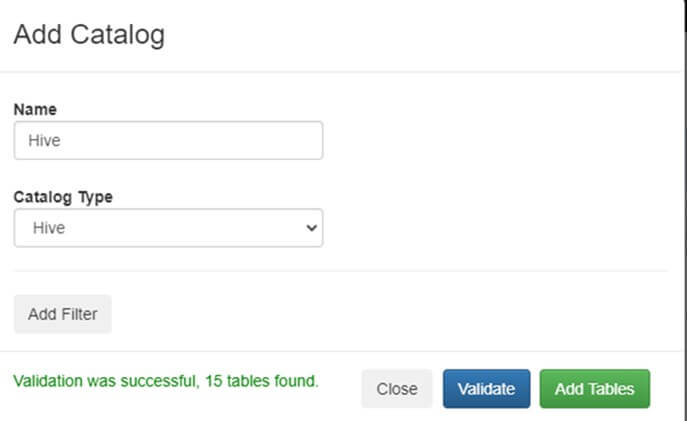
Hive catalog’u için bir isim verilir ve Catalog Type kısmından “Hive” seçilip “Validate” butonuna basılır. Validate ettikten sonra şekilde görüldüğü gibi “Validation was successfull, 15 tables found” sonucunu döndürür. “Add Filter” butonundan veri tabanı ve tablo bilgilerini girerek tabloları filtreleyebilirsiniz. Bu işlemlerden sonra “Add Tables” butonuna basılır ve işlem tamamlanır.
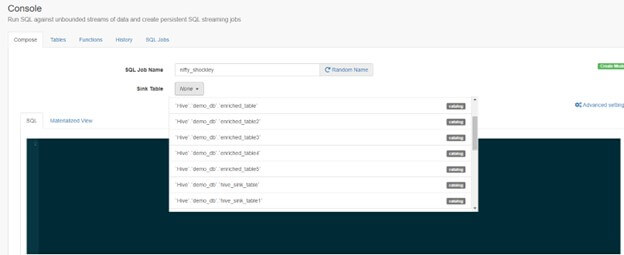
Catalogs olarak Hive tablolarını ekledikten sonra SQL Console ekranında Sink Table listesi yukarıdaki şekilde görünmektedir.
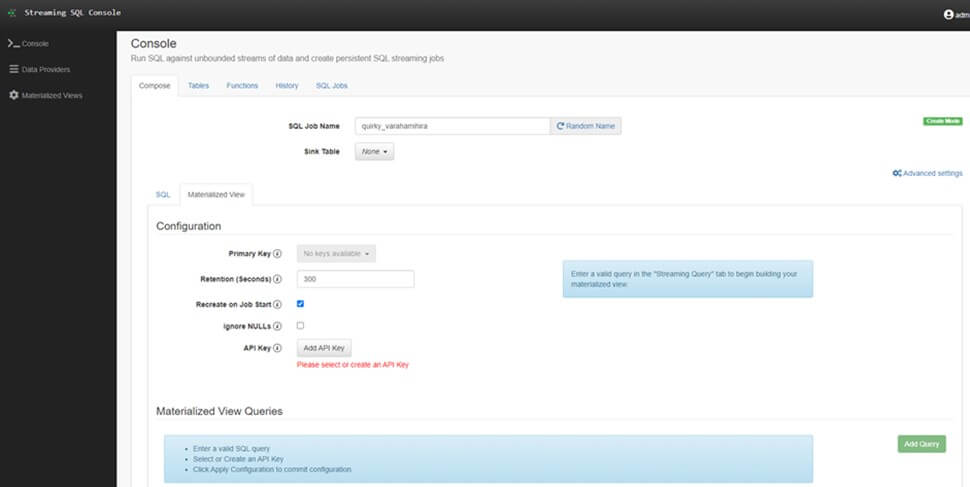
SQL Console üzerinde job çalıştırdıktan sonra sonuçları kalıcı bir hale getirmek için Materialized Views oluşturabiliriz. Materialized View Queries oluşturduktan sonra ilgili web linkine gittiğimizde akan verilerin sonuçlarını görebiliriz.
SSB Uygulama Örneği
Bu örnekte, SQL Console üzerinde sorgu yazıp Kafka’dan gelen gerçek zamanlı verileri Hive tablosuna gönderip Hue servisi ile görselleştirme adımları anlatılmıştır.
Adım 1: Kafka tablosu oluşturma
- Console -> Tables -> Add table
- Tablo ismi verilir. Data Provider kısmında SSB kurulurken Cloudera Manager tarafından eklenen Kafka cluster’ı seçilir. Topic name kısmında Kafka cluster’ında var olan topicler listelenir. Bu listeden ilgili topic’i seçip Kafka schema kısmının otomatik doldurulması için Detect Schema butonuna tıklanır ve Kafka topic içerisindeki schema otomatik olarak oluşturulur.
- Event Time kısmında “Use Kafka Timestamps” seçeneği bulunur. Kafka timestamps bilgisi, verinin ilgili topic’e hangi zaman diliminde yazıldığı bilgisini içermektedir. Bu bilgiyi de Hive tablosuna yazabiliriz fakat demoda bu bilgiyi kullanmayacağız. Bu sebepten dolayı “Use Kafka Timestamps” seçeneği kaldırılır.
- Properties kısmında “Default Read Position” değeri “Beginning of topic” olarak seçilir. Çünkü topici en baştan okumak istiyorum.
- Save Changes butonuna basılır ve tablo oluşturulur.
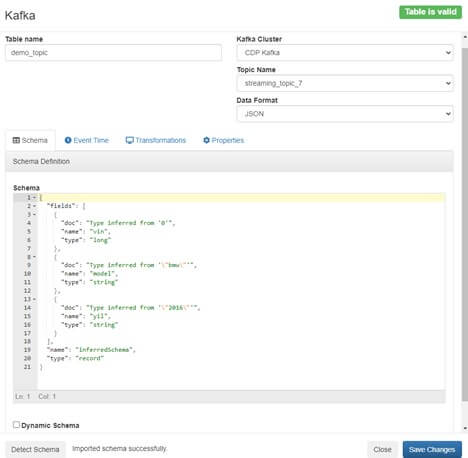
Adım 2: SQL Sorgusu Yazıp Akışı Başlatma
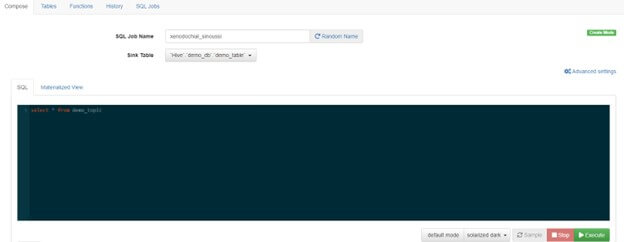
- Console ekranında SQL sorgusu yazılır
- Sorguyu çalıştırmadan önce “Sink Table” kısmından veriyi göndereceğimiz Hive tablosu seçilir.
- Sorgu “Execute” edilir.
Sorgu execute edildikten sonra Logs ekranı üzerinde aşağıdaki şekilde bir çıktı görünmesi gerekmektedir.

Adım 3: Apache Hue Servisi kullanarak Hive tablosunu görselleştirme
- Cloudera Manager üzerinden Apache Hue arayüz ekranına geçilir.
- demo_table tablosunun select çıktıları aşağıdaki gibidir.
Yukarıdaki şekilde görüldüğü gibi Kafka topic’inde bulunan verileri sürekli olacak şekilde Hive tablosuna aktardık. Kafka topic’ine her yeni veri geldiğinde ilgili job çalıştığı sürece Hive tablosuna veri gelmeye devam edecektir. Çalışan jobı durdurmak için Console -> SQL Jobs -> İlgili job -> Stop adımlarını takip edebilirsiniz.
Cloudera, veri yaşam döngüsü olarak adlandırdığımız bütün süreci baştan uca sizin için kolaylaştıracak servisler ile birlikte gelir. Yukarıda değindiğimiz SSB söz konusu servislerden sadece bir tanesidir. Cloudera SQL Stream Builder ile ilgili tüm sorularınız ve ayrıntılı bilgi için GTech Büyük Veri ve Analitik uzmanlarımız ile iletişime geçebilirsiniz.
Yazar: Mehmet Can Yılmaz, GTech Büyük Veri ve İleri Analitik Danışmanı
Muammer Gülerce, GTech Büyük Veri ve İleri Analitik Danışmanı