Apache Spark Nedir, Kurulumu ve Uygulama Örneği

Apache Spark Nedir, Kurulumu ve Uygulama Örneği
Apache Spark, büyük veri kümeleri üzerinde paralel olarak işlem yapılmasını sağlayan, Scala dili ile geliştirilmiş açık kaynak kodlu kütüphanedir.
Disk bazlı çalışma yapısına sahip olan “MapReduce”un oluşturduğu performans maliyetlerinin çözümüyle ortaya çıkan Spark, bellek içi veri işleme özelliğiyle büyük veri uygulamalarında Apache Hadoop’tan daha hızlı çalışabilmektedir. Dolayısıyla verileri işlerken diskten veri okumadan veya diske veri yazmadan bellekte tutmasıyla Spark’ın analitik motorunun daha hızlı işlemler yapabildiğini söylemek mümkündür. GTech’in bu yazısında, Apache Spark’ın işlevi, öne çıkan özellikleri ve sağladığı faydaları aktaracağız.
Bellek içi veri işleme, Spark’ın temel programlama özeti olan “RDD (Resilient Distributed Datasets)”ler ile yapılmaktadır. RDD’ler elemanlar üzerinde paralel olarak işlemlerin yapılmasını sağlayan, makineler arasında bölünmüş veri koleksiyonlarıdır. RDD’ler oluşturularak diskteki veriler, geçici belleğe taşınmaktadır. Bu RDD’ler üzerinde yapılacak senaryolara göre sorgular yazılarak veriler işlenmektedir.
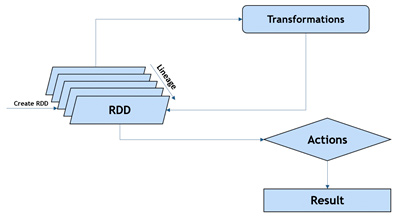
Makine öğrenimi, akış verileri, grafik verileri gibi farklı konularda büyük veri uygulamalarında kullanılabilen Spark, veriyle ilgili çalışan kullanıcılar tarafından tercih edilmektedir. Ayrıca Java, Scala, Python gibi farklı yazılım dilleri ile uygulamalar geliştirilmesine olanak sağlamasıyla popülerliğini artırmaktadır.
Apache Spark Kütüphaneleri
Spark, görselleştirme (grafik işleme), makine öğrenimi, akış işlemleri için çeşitli kütüphanelere sahiptir. Bu kütüphaneler:
Graphx: Grafik sorunlarını çözmek için tasarlanmış ve paralel hesaplamaları sağlayan bir algoritma kütüphanesidir. Grafik olarak bilinen temel bir yapıya sahiptir. Veriler üzerinde gelişmiş analitik prosedürlerin gerçekleşmesine izin verir ve grafiğin görünümlerini görselleştirebilmekte ve verileri ayırt edebilmektedir.
Mlib: Makine öğrenimini bir tür analize dönüştürerek istatiksel işlemler yapılmasını sağlamaktadır.
Streaming: Gerçek zamanlı veriler ile işlemler ve analizler yapılmasına olanak tanımaktadır.
Spark SQL: Yapılandırılmış veriler (structured data) için kullanılan ilişkisel sorgular için uygundur. “Join” işlemlerinde çok hızlı olan bu kütüphane, Spark SQL dilini kullanarak verilerin işlenmesini kolaylaştırmaktadır.
Apache Spark Streaming
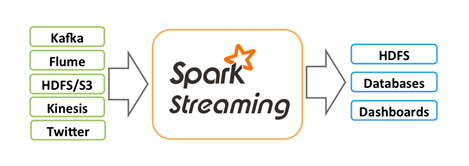
Spark Streaming, canlı veri akışlarının ölçeklenebilir, yüksek verimli, hataya dayanıklı akış işlemesini sağlayan temel bir yapıdır. Kafka, Kinesis veya TCP soketleri gibi farklı kaynaklardan verileri alarak karmaşık algoritmalar ile işleyebilmektedir. Bu verileri dosya sistemlerine, veri tabanlarına ve dashboard’lara gerçek zamanlı olarak aktarabilmektedir.
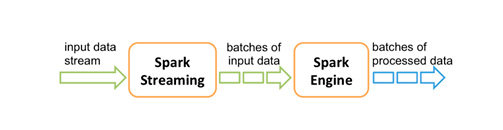
Spark Streaming, aldığı gerçek zamanlı veriyi “mikro batch”lere ayrırarak Spark Engine kısmına yönlendirir. Akışı oluşturmak için Spark Engine tarafından veriler işlenir ve nihai sonuç akışın çıktısına gönderilir.
Spark Streaming, sürekli bir veri akışını temsil eden Ayrıklaştırılmış Akış veya DStream adı verilen üst düzey bir soyutlama sağlar. Kaynaktan verileri okuyan ve RDD’lerin üzerine inşa edilen DStream, bir RDD dizisi olarak temsil edilmektedir. RDD’ler DStream üzerinde belli bir zaman aralığındaki veriyi tutmaktadır.
Apache Spark Uygulama Örneği
Örnek olarak çalışan bilgilerin bulunduğu bir veri setini, iki farklı şekilde nasıl ele alınabileceği Apache Spark SQL kullanılarak gösterilmiştir.
Metin dosyası uzantısı olan TXT dosyasında bulunan verileri aşağıdaki şekilde okunması sağlanmış ve SparkConf ve JavaSparkContext ile Spark konfigürasyon ayarlamaları yapılmıştır.

“Employee” adında bir başlangıç RDD oluşturulmuştur ve genellikle bunu dosya sisteminden ya da bir tür veri kaynağından yaratılmaktadır.

Oluşturulan ilk RDD, Spark‘ın etki alanına sokularak tablo şeklinde kaydedilmiştir.

Daha sonra farklı bir RDD oluşturulmuştur. Burada ki amaç ilk RDD’de oluşturulan tabloyu işlemek üzere sorgulamaktır. Kullanılan sorguda basit olarak yaşı 13 ila 19 arasında olan çalışanlar sorgulanmaktadır. Ayrıca farklı RDD’ler oluşturularak sorgular genişletilebilir.

Aynı işlemler farklı şekillerde yapılabileceği gibi, veriler de farklı şekilde okunabilmektedir. Dolayısıyla yukarıda yapılan işlemlerde kullanılan veri seti “JSON (JavaScript Object Notation)” formatında da yapılabilmektedir. Fakat çoğunlukla benzer yanları olsa da kullanım şekillerinde farklılıklar göstermektedir.
JSON dosyasında bulunan aynı veri seti için yapılacak işlemler aşağıdaki gibidir;
Yukarıdaki adımlardan farklı olarak burada ilk oluşturacağımız RDD’ de dosyayı tanıtmak olacaktır.

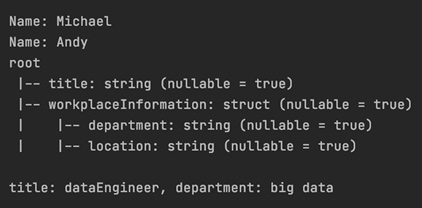
Ayrıca veri setinde bulunan alanlar aşağıdaki kod parçacığı ile veri tipleri görüntülenebilmektedir.

Yine önceki işlemde yapıldığı gibi oluşturulan RDD bir tablo olarak kaydedilip, bu tabloyu sorgulanmak üzere yeni bir RDD oluşturulmuştur.

İşlemlerin bu adımına kadar olan kısım, çalışmanın ilk kısmının JSON (JavaScript Object Notation) formatı şeklinde nasıl alınabileceğidir. Alternatif olarak list şeklinde yeni bir JSON oluşturulup, yeni bir RDD ile bu JSON verisi tablo şeklinde kaydedilmiştir. Buradaki amaç, işlemlerin sonunda farklı tabloda, çalışan bilgilerini yapılan sorguya göre bulduğumuz ilk sonucun bilgileri olarak işlemlerin sonuna yazdırabilmektir. Burada yapılan çalışmada olaylar ayrı ayrı ele alınmıştır fakat farklı senaryolarla “join”leme işlemleri de yapılabilmektir.

Çıktı
Apache Spark hakkında bilgi vererek uygulama örneğiyle kurulumunu detaylı açıkladık. GTech Büyük Veri ve İleri Analitik konusunda uzman ekibimiz ile büyük verilerin analizinde ve hızlı bir şekilde işlenmesinde kullanılan spark uygulamaları hakkında detaylı bilgi için bize ulaşabilirsiniz.
Yazan:
Kulilik Süer, GTech Büyük Veri ve İleri Analitik Danışmanı
Kaynakça
Learn Apache Spark from Scratch – Udemy
https://mesutozen.wordpress.com/2015/05/24/apache-spark-streaming/
https://spark.apache.org/docs/latest/streaming-programming-guide.html
https://dergipark.org.tr/en/download/article-file/623129
https://www.ibm.com/cloud/learn/apache-spark
https://intellipaat.com/blog/tutorial/spark-tutorial/programming-with-rdds/