
In today’s dynamic business landscape, speed and accuracy are no longer just choices, they are the keys to sustainable competition. If your business is struggling with the following bottlenecks, EyeQube Engine is here to lead your digital transformation:
Stop Losing Time to Competition: Are your decision cycles lagging behind the market? When customers are forced to wait, they pivot to competitors. Turn decision speed into your ultimate competitive advantage.
Break Free from IT Dependency: Don't let your strategy sit in an IT backlog for months. Empower your business units to manage their own rules and logic, reducing time-to-market from weeks to hours.
Eliminate Costly Manual Errors: Are human-led processes creating financial risks and operational drain? Automate your complex decision logic to ensure 100% consistency and minimize high-stakes errors.
Audit-Ready, Stress-Free Operations: Tired of struggling to track "who decided what and why?" With a complete digital audit trail and full regulatory compliance (GDPR, Banking Regulations, etc.), you can ensure transparency and peace of mind.







Overview - Home: Access Flows, Panels and Metadata pages
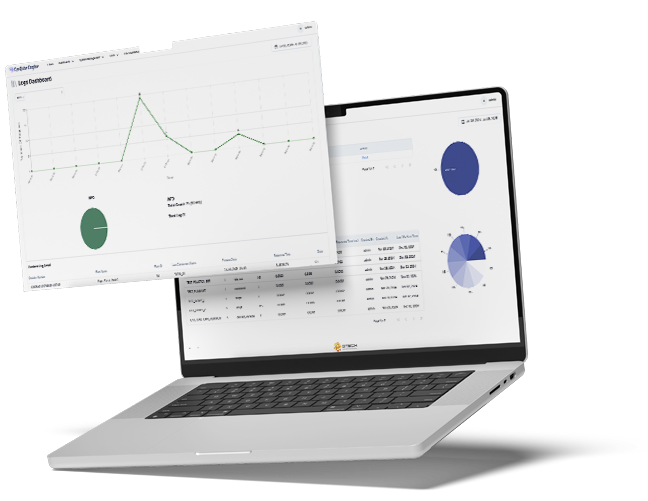
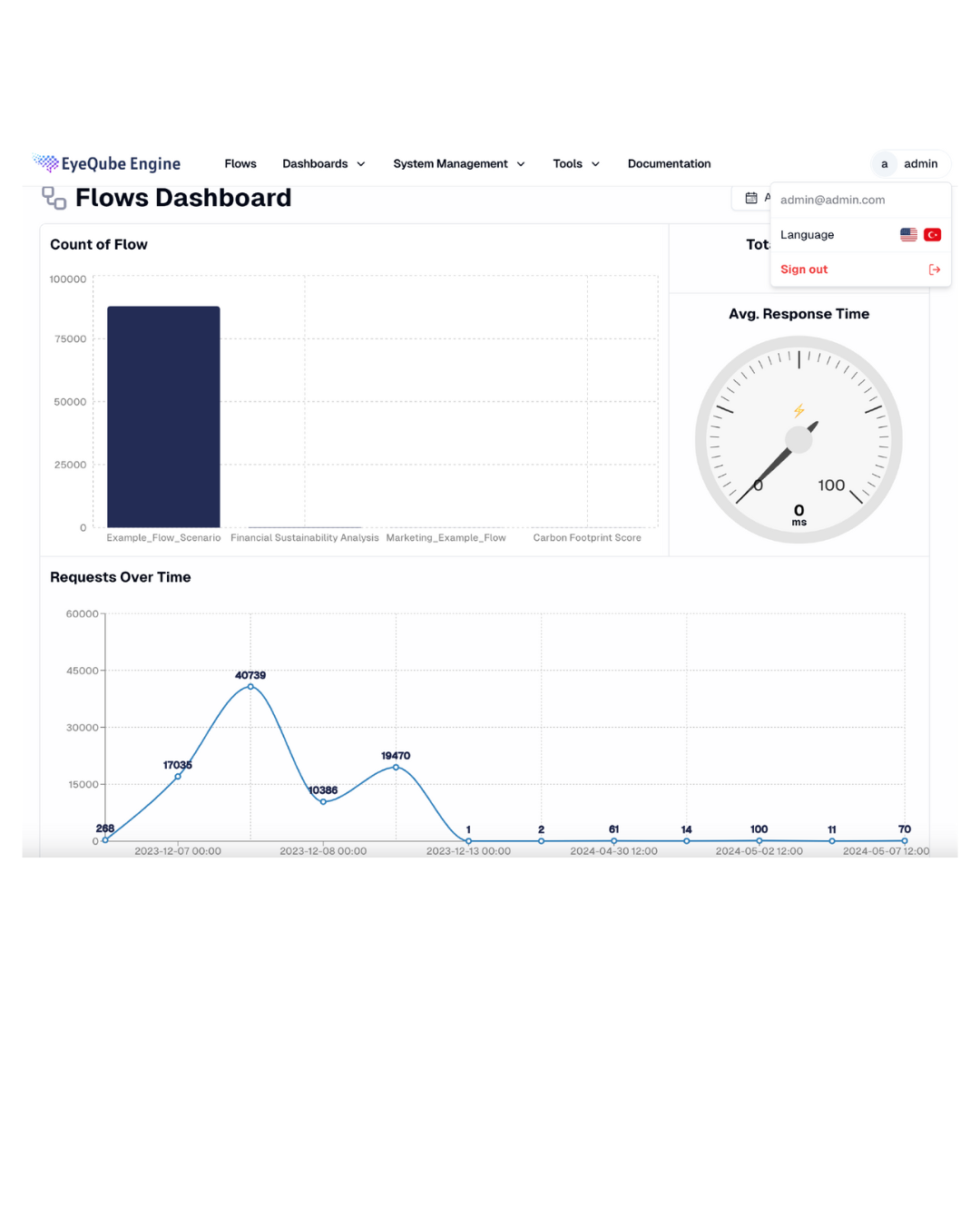
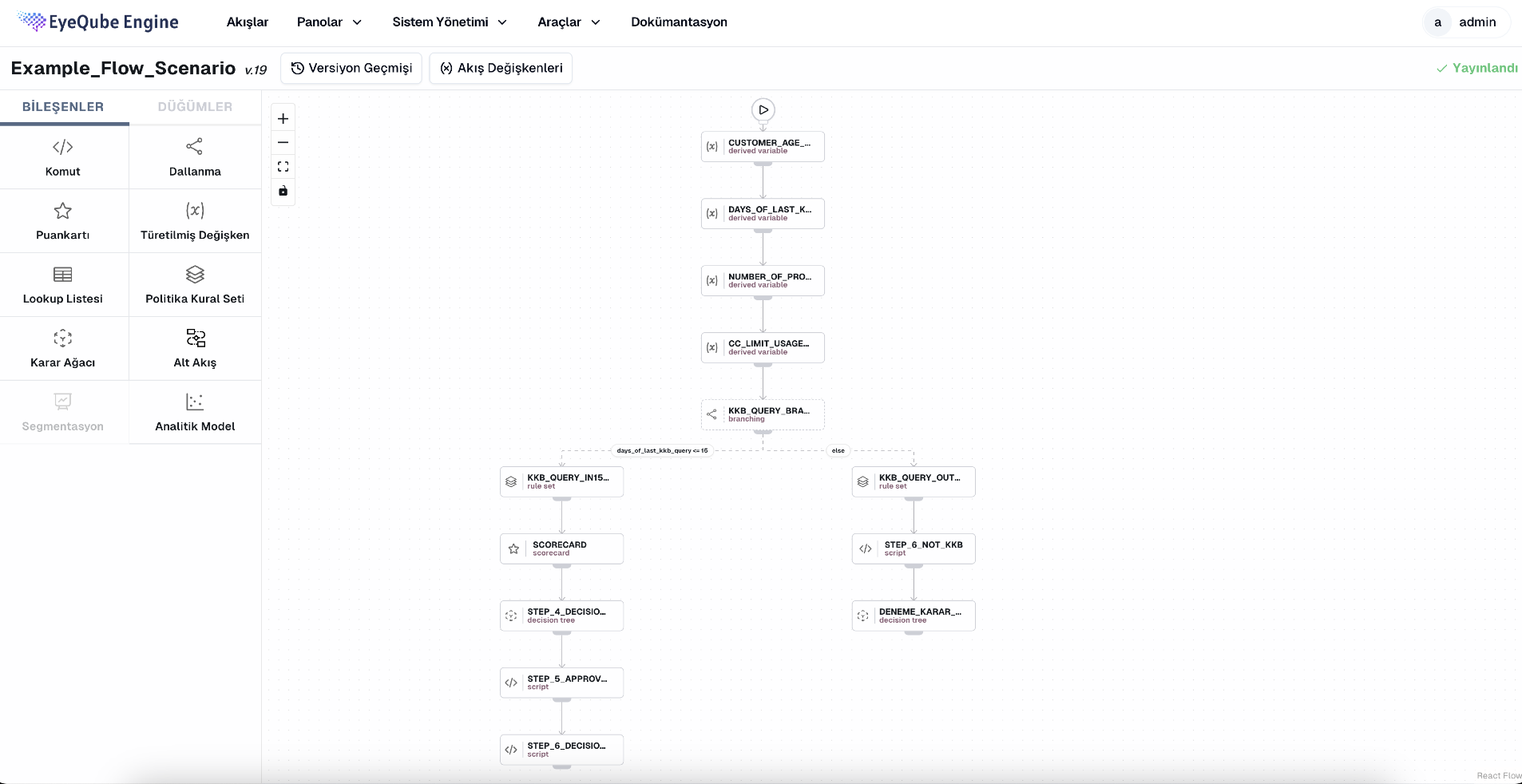
Management - Flow Screen: You can manage your flows from here
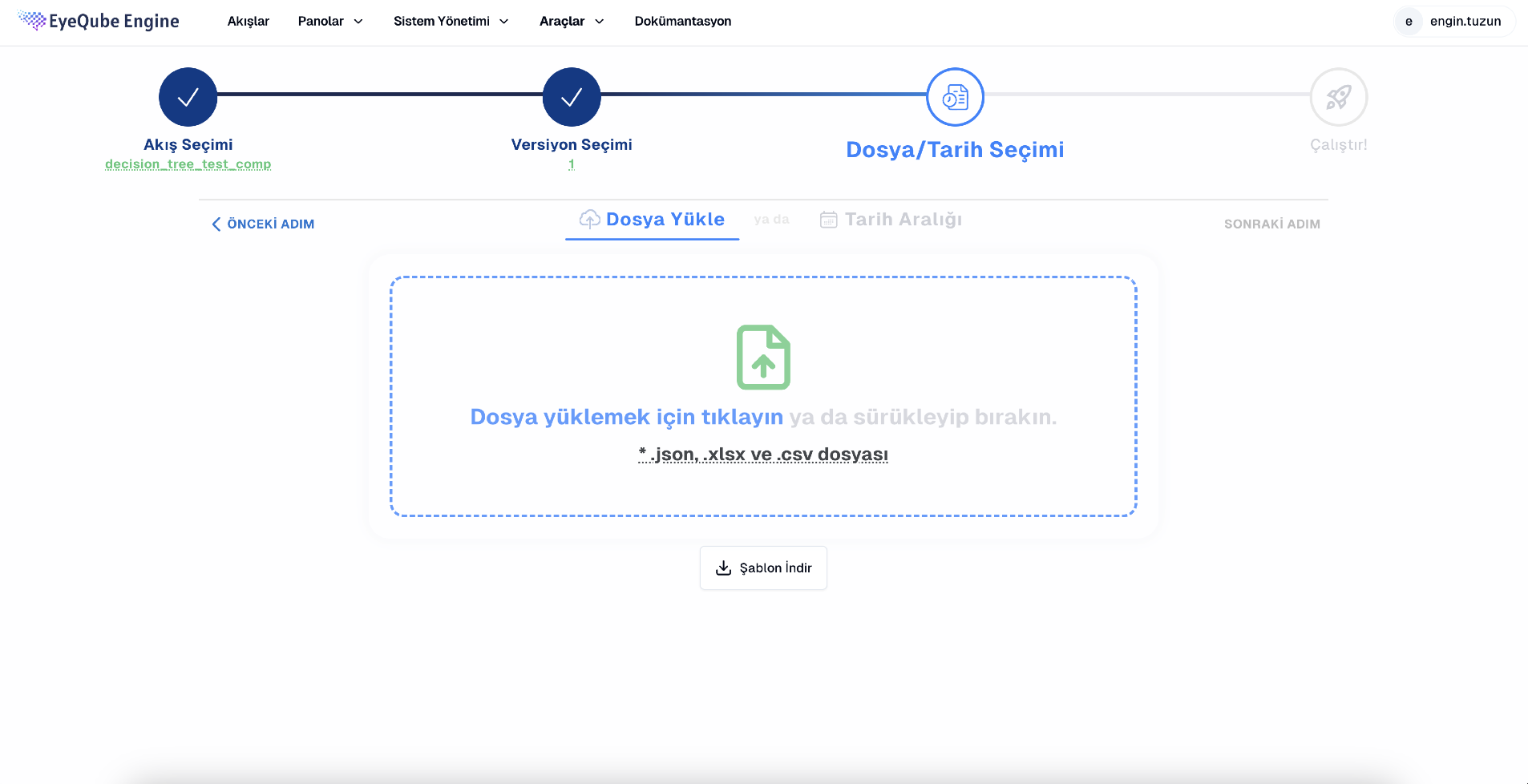
Testing - Simulation: Download the appropriate file for your flow and run simulations
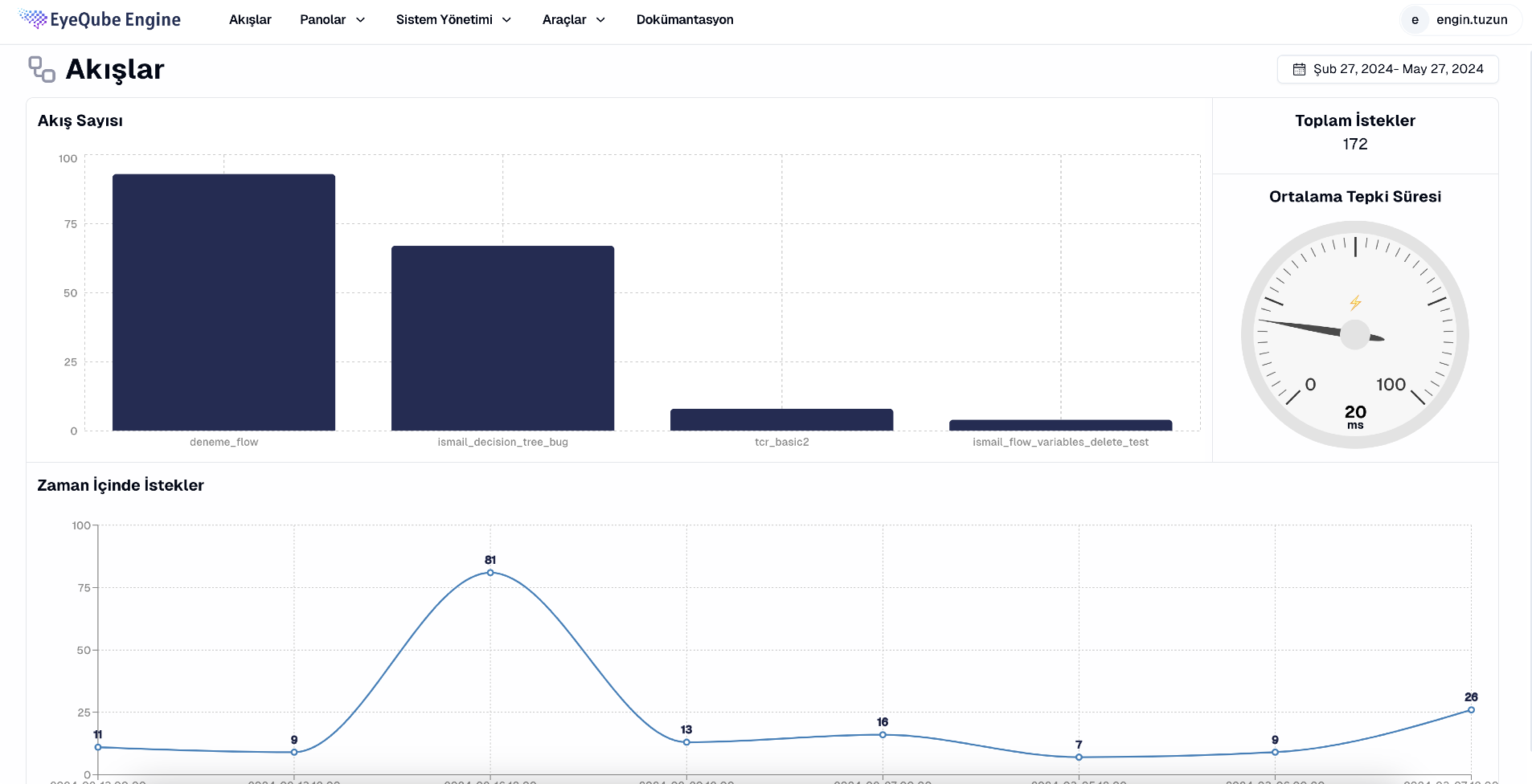
Data - Flow Panel: Easily view data related to your flow
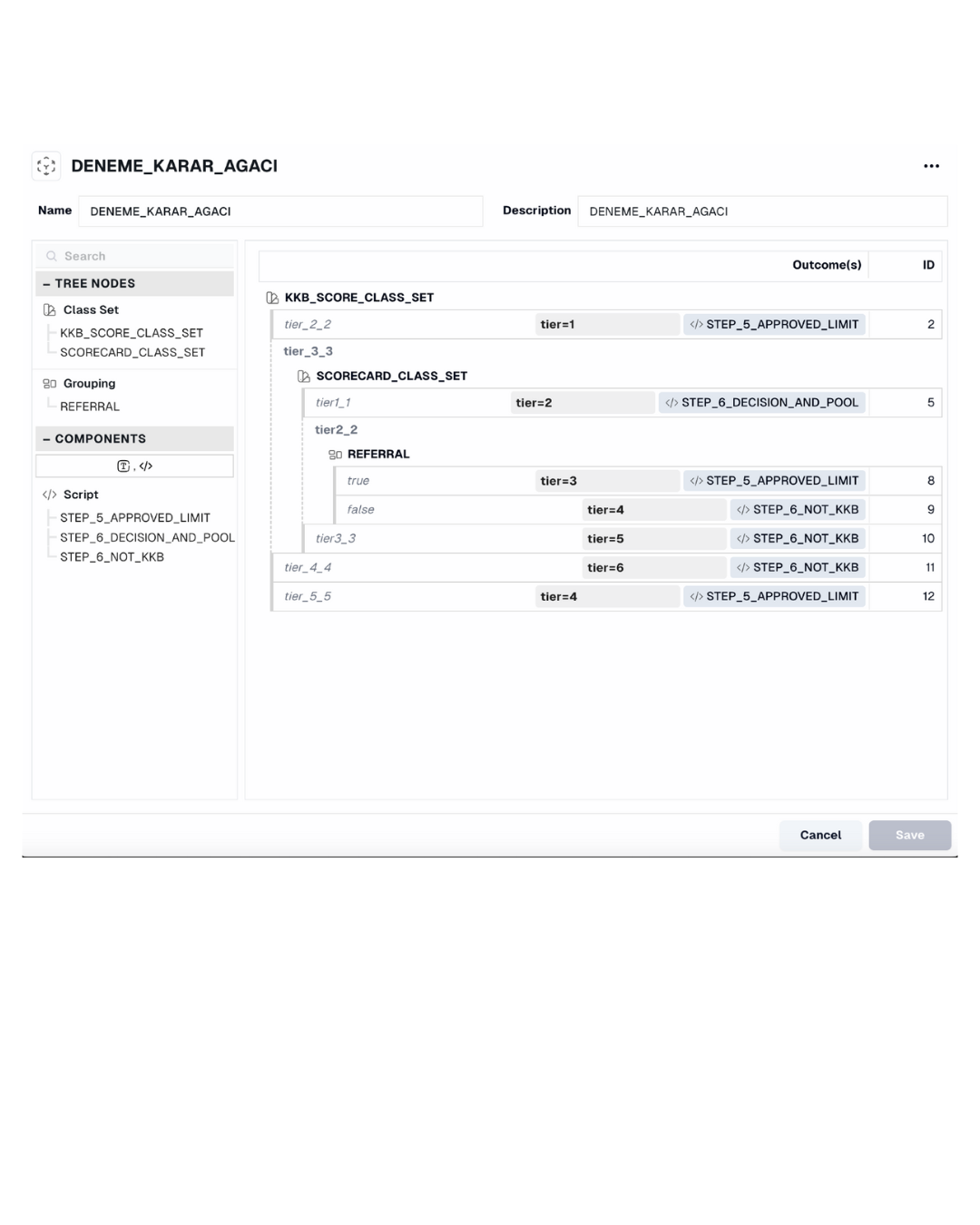
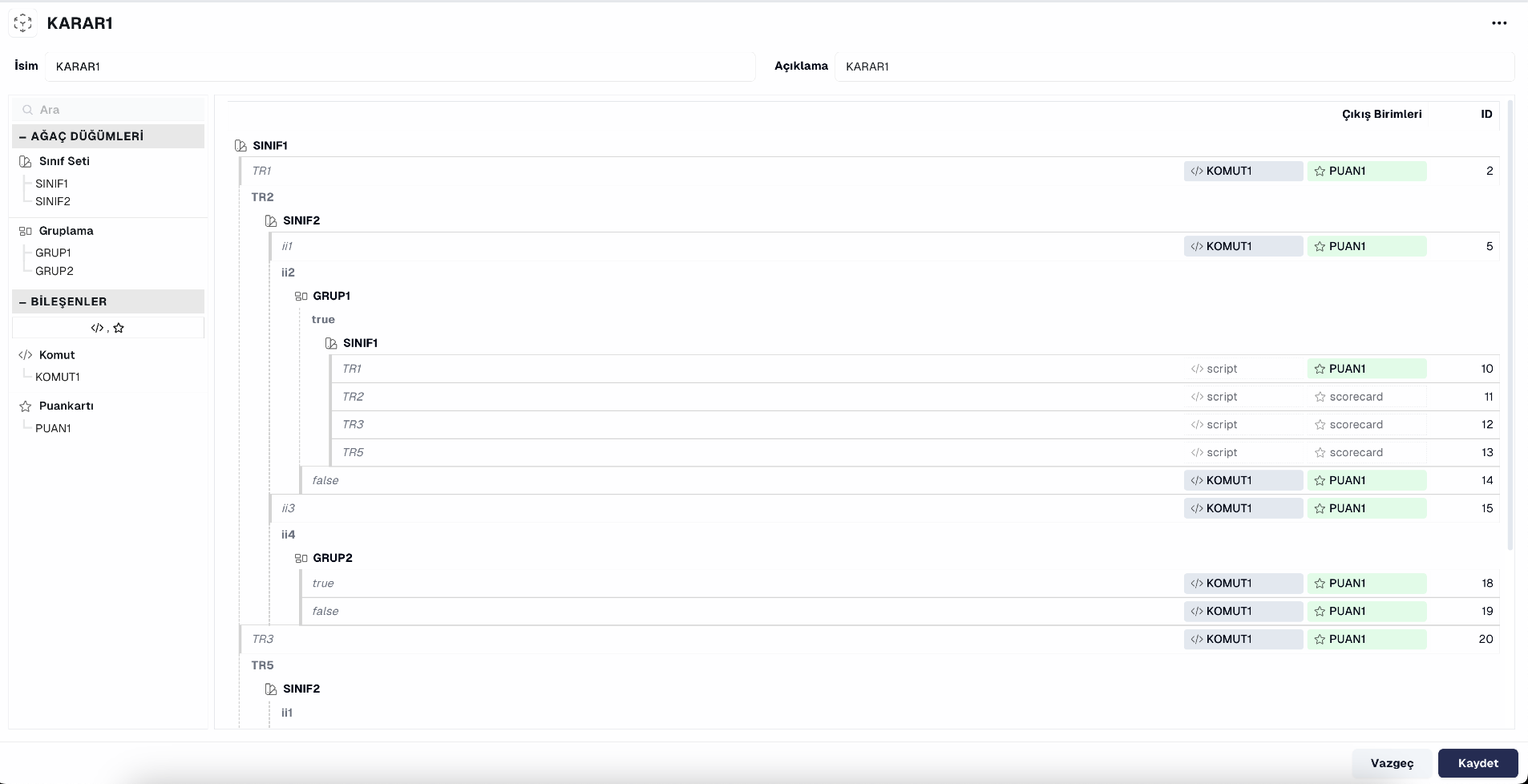
Logic -Decision Tree: Create and manage any setup you want in decision flows
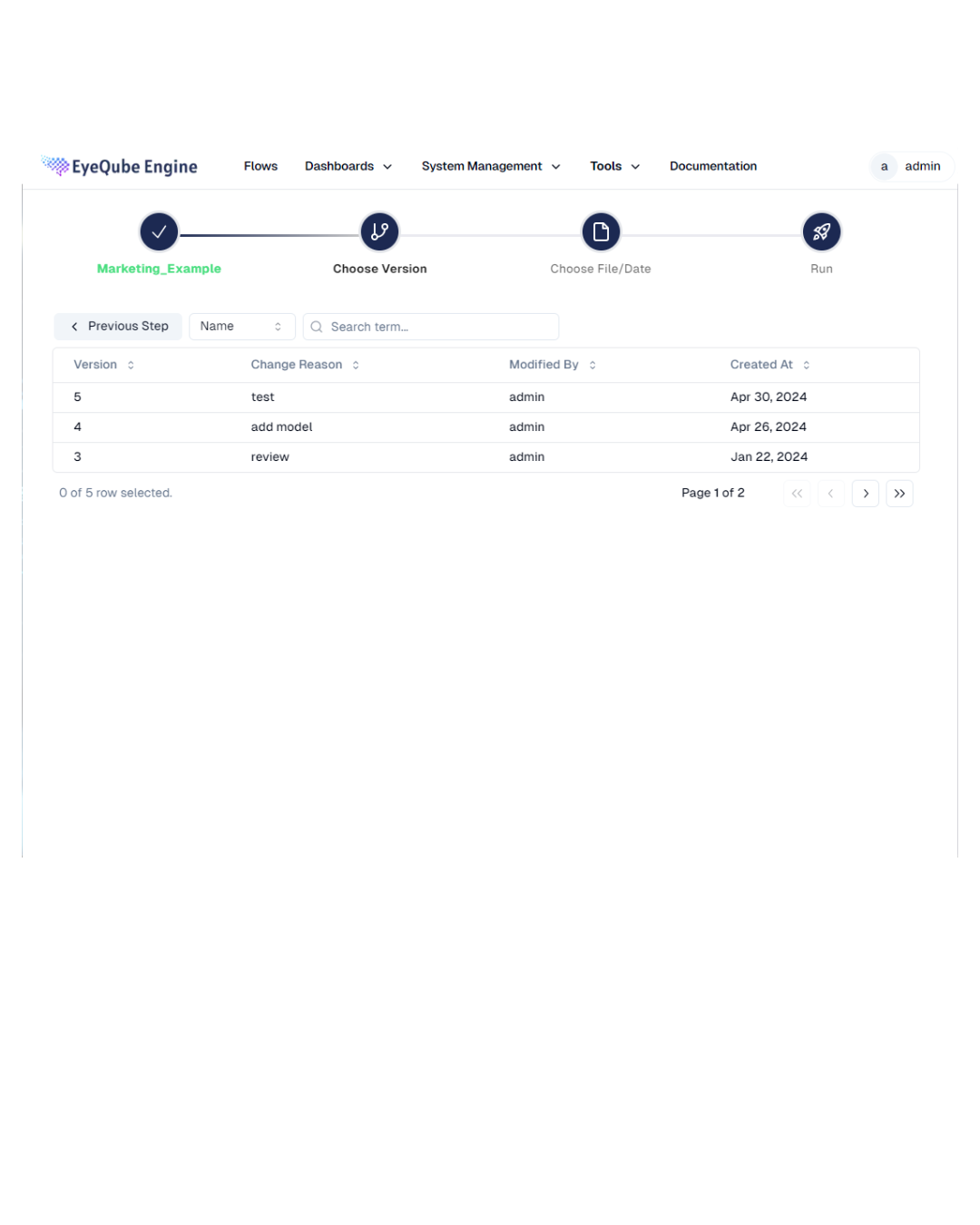
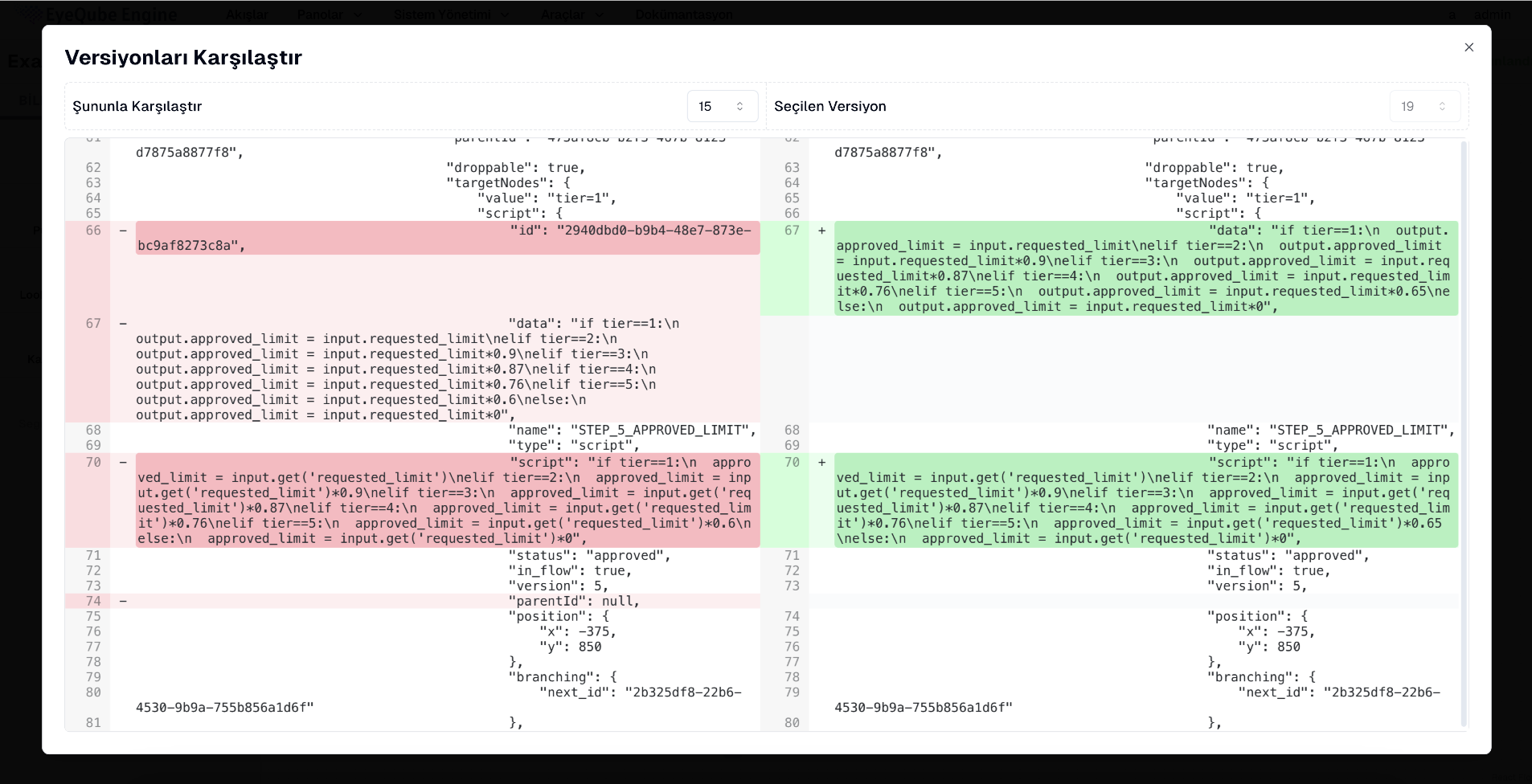
Analysis - Version Comparison: Compare selected different version




Since it has a flexible structure, it is very easy to manage the data dictionary. It does not require software changes.
Creating flows with a drag-and-drop structure is very easy. Many flows can be designed using 10+ components.
Flows can be tested with synthetic data before going live, and results can be viewed.
Every change is recorded and versioned. At any time, it is possible to see who made which change and when.
VIP or blacklists can be created and used for control purposes in flows.
A secure and regulatory-compliant mechanism is provided for changes in flows and production, ensuring both approval and control.
Changes can be applied either directly from the application or through export/import rules, allowing for seamless deployment.

With our expert team that you trust to add value to your data we anticipate the importance of data for your business and reflect our deep field experience to your business by using every layer, field, and meaning of the correct information.
We are here to produce specially designed solutions for your needs and to apply them carefully to your business.

EyeQube Engine is designed with the ability to make complex decisions based on business rules, data and machine learning technologies. Thanks to its user-friendly interface and flexible authorization management features, it can be customized to meet the needs of many businesses.
For example, it can be used in the process of setting an offer price for an insurance company, in the process of approving a loan application for a bank, in the process of customer segmentation for a retail company, and in many similar scenarios. Decisions are real-time and reliable. Thus, enterprises increase productivity by making fast and accurate decisions accompanied by EyeQube Engine.