iQube Retail ile Ölçeklendirilmiş Zaman Serisi Modelleri

En son ne zaman semt pazarına gidip alış veriş yaptınız?
Pandemi döneminin getirdiği alışkanlıkların ve teknolojik gelişmelerin hayatımıza etkileri gün geçtikçe artıyor. Yeni dönemde günlük hayatımızı etkileyen en önemli alışkanlıklardan birisi de alışveriş yöntemlerimizdeki değişim oldu. Online olarak, evden bile çıkmadan alışveriş yapmak hayatımıza büyük kolaylıklar getirdi. Tüketicinin davranış alışkanlıklarındaki bu değişim perakende sektöründe de büyük dönüşümü beraberinde getirdi. Perakende sektöründe hizmet veren firmalar, müşterilerinin ihtiyaçlarına yönelik kendilerini hazırlama ve aksiyon alma konusuna hızlı bir şekilde adapte olmaları gerekiyor. Bunun için; mağaza, kategori, ürün gurubu ve ürün bazında gelecek öngörülerinin tutarlı olması, hem ürün hem de müşteri memnuniyeti açısından bir gereklilik haline geldi. Bu yazımızda, mağaza ve ürün bazında büyük ölçekli zaman serisi öngörü modellerini açıkladık.
Çalışmamızda ele aldığımız problemin çözüm adımlarından birisi olarak, müşterilerin talep edecekleri ürün miktarının öngörüsü ve bu öngörülerin gerçekleşmesini sağlayan iki yapay öğrenme algoritmasını (Prophet ve XGBoost) Spark üzerinde karşılaştırdık. Bu iki algoritmayı seçme sebebimiz; ikisinin de zaman serileri üzerinden hızlı ve hata oranı düşük sonuçlar vermeye daha yatkın olmalarıdır. Spark kullanmamızın sebebi ise; yapılacak veri hazırlık işlemlerinin paralel bir şekilde çalışarak performansımızı artırması ve hızlı bir şekilde çıktı almamızı sağlamasıdır.
Çalışmamızda Spark’ı öncelikle standalone mode ile sonrasında da cluster mode ile çalıştırarak hem Prophet hem de XGBoost için karşılaştırmalı sonuçlar elde ettik.
Veri Yapısı
Bir zincir markete ait olan veriler ile, şube ve ürün bazında analizler gerçekleştirdik. Ürünlerin günlük satış miktarı verilerini kullanarak; haftalık ve aylık olarak satış miktarlarının öngörülmesi ve bu öngörü sonuçlarının raporlanması konusunda çalışmamızı yürüttük. Perakende sektöründen elde ettiğimiz veri, zaman serisi odaklı bir yapıya sahiptir.

Hazırladığımız veri setini modelleme aşamasına geçmeden önce bazı hazırlık aşamalarından geçirdik. Öncelikle ürün ve şube bazında analizler gerçekleştirdik. Bu analizlerimiz sonucunda iadeli ürünler, en son satışı yıllar önce yapılmış ve artık satılmayan ürünler, satışa yeni başlamış ürünler, uzun süredir satışı yapılan ürünler, dönemsel olarak satışı olan ürünler gibi bir çok farklı senaryoyla karşılaştık. Her birinin çözümü için ürün bazında çözümler sunarak analizimizi tamamladık.
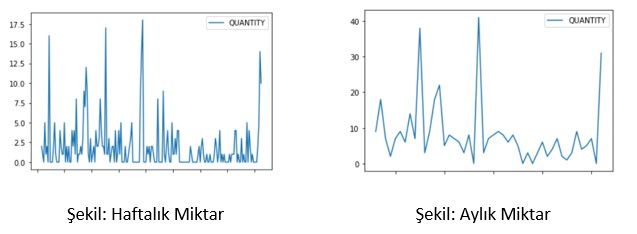
Veri hazırlığını tamamlamak için analizden edindiğimiz sonuçlarla, uzun zamandır satışı olan ürünler ve kısa zaman periyodunda satışı olan ürünler olarak iki kategori oluşturduk. Bu iki kategori içinde farklı tahmin yöntemleri uyguladık.
Modelleme
Modelleme aşamasında Spark’ı yerel bilgisayarımızda (standalone mode) kullanarak Prophet ve XGBoost algoritmalarıyla ürettiğimiz modellerin çalışma performansı ve hata payları olarak çıkarttığımız sonuçlar aşağıdaki tabloda yer alıyor.
| Prophet Haftalık | XGBoost Haftalık | Prophet Aylık | XGBoost Aylık | |
| Modelleme Süresi | 6:39:41.697370* | 4:30:55.380996* | 10:02:27.117752* | 2:47:34.240876* |
| MAE | 1.75 | 1.58 | 10.76 | 4.33 |
| Max Error | 688.50 | 253.50 | 24715.00 | 2342.00 |
Tablodan da görebileceğiniz gibi XGBoost, hem haftalık hem de aylık yapılan tahminleme modellerinde Prophet’a göre çok daha performanslı ve daha düşük MAE değerlerine ulaştı. Bu istatistikler sonucunda XGBoost ile devam etmeye karar verdik.
Çalışmanın devamında farklı bir soruyu cevaplamak için Spark’ı cluster mode kullanarak denememizi gerçekleştirdik. Bunun için öncelikle bir cluster yapısı kurduk. Yapımızı bir master ve beş worker olacak şekilde ayağa kaldırdık. Burada yaptığımız çalışmada XGBoost kullanarak aylık tahminleme yaptık.
XGBoost Aylık | Standalone Mode | Cluster Mode |
Modelleme Süresi | 2:47:34.240876 | 21:02.12131 |
Bu tablodan da göreceğiniz gibi cluster mode ile aldığımız sonuçlarda yaklaşık yüzde seksen beşlik bir performans gelişmesi gördük.
Çıktılar ve Görselleştirme
Geliştirilen modeller kullanılarak gerçekleştirilen öngörü sonuçlarını görselleştirmek için bir rapor ekranı hazırladık ve web üzerinden erişilebilir hale getirdik.
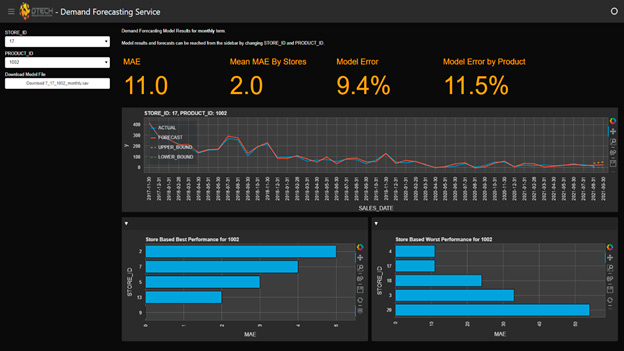
Böylece, kullanıcıların yapılan çalışmanın çıktılarına daha basit bir ekrandan ulaşarak kendi kararlarını almalarına olanak sağlanmış oldu.
Çalışmamızın sonucunda uçtan uca, veriye dayalı ve ölçeklenebilir bir öngörü ürünü oluşturmuş olduk. Bu ürün ile perakende sektöründe rahatça kullanabilecek öngörü çıktıları ile firmaların planlarını nokta atışı olarak ürün ve şube bazında yapmalarına olanak sağladık. GTech Wiseboard Retail ürünü hakkında detaylı bilgi almak için alanında uzman ekiplerimize ulaşabilirsiniz.
Hazırlayanlar:
Ufuk Yılmaz, GTech Veri Bilimci