Oracle 23AI, Cohere ve Flask ile Retrieval-Augmented Generation (RAG) Sistemi Oluşturma

Retrieval-Augmented Generation (RAG) Nedir?
Retrieval-Augmented Generation (RAG), geleneksel bilgi erişimini üretken modellerle birleştiren bir tekniktir. Bu yaklaşım, harici kaynaklardan (örneğin bir veritabanı veya belgeler) bağlam alarak yanıtların ilgili ve doğru olmasını sağlar.
GTech’in geliştirdiği Custom RAG projesi, sistem kullanıcının sorgusuna dayanarak Oracle 23AI veritabanından ilgili belgeleri çeker. Daha sonra Cohere’nin Büyük Dil Modellerini (LLM) kullanarak detaylı yanıtlar üretir. İş akışı, hem belgeleri hem de sorguları vektörlere dönüştürmeyi, bunları karşılaştırmayı ve sonuçları yeniden sıralayarak en ilgili bilginin nihai yanıtla kullanılmasını sağlar.
Temel Bileşenler
Cohere ile Vektör Gömüleri (Embeddings)
Bu sistemin temelinde Cohere’nin gömüleri (embeddings) yer alır. Bunlar, metnin anlamını yakalayan yoğun vektör temsilleridir. Cohere, belgeleri ve sorguları vektörlere dönüştüren bir gömü modeli sunar (örneğin, projede kullanılan cohere.embed-multilingual-v3.0). Bu gömüler, belgeler ve sorgular arasındaki benzerliği ölçmek için kullanılır.
Bir PDF belgesi işlenirken, metin yönetilebilir parçalara ayrılır, temizlenir ve ardından gömülere dönüştürülür. Bu gömüler, Oracle 23AI veritabanında vektör veri türü kullanılarak saklanır. Oracle’ın 23AI DB vektör veri türü, büyük veri kümelerinde benzerlik aramaları için yüksek performanslı depolama, indeksleme ve sorgulama sağlar.
Başlangıçta, Oracle Cloud Infrastructure (OCI) üzerinde Frankfurt bölgesini kullanarak gömüler oluşturulması denendi. Ancak, bu bölge cohere.embed-multilingual-v3.0 modelini desteklemiyordu. Bu sorunu çözmek için, modelin tam olarak desteklendiği Chicago bölgesine geçiş yapıldı ve uygulama sorunsuz bir şekilde ilerletildi.
Oracle 23AI Veritabanından Bilgi Çekme
Bir sonraki adım, Oracle 23AI veritabanından ilgili bilgileri çekmektir. Bunun için sorgu vektörü, saklanan belge vektörleriyle Dot Product (Nokta Çarpımı) benzerlik araması kullanılarak karşılaştırılır. Bu yöntem, vektör mesafesine göre en ilgili 10 belgeyi belirler.
Belgeler, hem metinleri hem de gömüleriyle birlikte Oracle veritabanında saklanır, bu da ilgili içeriğin gerçek zamanlı olarak çekilmesini sağlar. Oracle’ın vektör veri türü, büyük belge gömü kümelerinde bile verimli depolama ve hızlı erişim sağlar.
Cohere’nin Yeniden Sıralama Modeli ile Belge Sıralama
İlgili belgeler çekildikten sonra, bunları sorguya göre en ilgili olanlara göre sıralamak gerekir. Cohere’nin yeniden sıralama modeli (rerank-multilingual-v3.0) kullanılarak yapılır.
Yeniden sıralama modeli, belgeleri ilgili olma durumuna göre sıralayarak en ilgili olanların nihai yanıt için seçilmesini sağlar. Bu model, sonuçları iyileştirmek ve üretilen yanıtın doğruluğunu artırmak için kritik bir rol oynar.
Cohere LLM ile Yanıt Üretme
İlgili belgeler çekilip yeniden sıralandıktan sonra, bir sonraki adım nihai yanıtı üretmektir. Bu görev için Cohere’nin LLM’lerini (örneğin: command-r-plus). LLM, sorguyu ve sıralanmış belgeleri girdi olarak alır ve sağlanan bağlama dayalı bir yanıt üretir.
Bu sistemin önemli bir özelliği, LLM’in üretken gücünü çekilen belgelerden gelen spesifik ve bağlam açısından zengin bilgilerle birleştirmesidir. Bu, üretilen yanıtın yalnızca sorguyla ilgili değil, aynı zamanda ilgili belgelere dayalı olmasını sağlar.
Flask ile Kullanıcı Arayüzü
Sistemi etkileşimli hale getirmek için Flask kullanarak basit bir web arayüzü oluşturulur. Kullanıcı, bir web formu aracılığıyla bir soru gönderir ve Flask sunucusu, arka uç fonksiyonlarını çağırarak sorguyu işler. Bu fonksiyonlar, ilgili belgeleri çeker, yeniden sıralar ve bir yanıt üretir.
Flask, ön yüz (HTML) ve arka uç arasındaki iletişimi ve yönlendirmeyi yöneterek kullanıcı için sorunsuz bir etkileşim sağlar. Bir soru sorulduğunda, arka uç sorguyu işler ve yanıtı, ilgili belgelerle birlikte kullanıcıya döndürür.
Sistem Nasıl Çalışır?
1- Kullanıcı web arayüzü üzerinden bir soru gönderir.
2- Sistem, sorguyu Cohere kullanarak bir gömüye dönüştürür.
3- Sorgu, Oracle 23AI veritabanında saklanan belge gömüleriyle karşılaştırılır (vektör veri türü kullanılarak).
4- En ilgili belgeler çekilir ve Cohere’nin yeniden sıralama modeli kullanılarak sıralanır.
5- Sistem, çekilen belgelere dayalı olarak Cohere’nin LLM’i ile bir yanıt üretir.
6- Yanıt, ilgili belgelerle birlikte kullanıcıya döndürülür.
İş Akışı:
Kullanıcı Sorgusu → Sorgu Gömüsü (Cohere Modeli) → Bilgi Çekme (Oracle 23AI Veritabanı) → En İlgili 10 Belge (Dot Product Benzerliği) → Belgeleri Yeniden Sıralama (Cohere’nin Yeniden Sıralama Modeli) → Yanıt Üretme (Ek Bilgiler/Belgelerle Bağlamda Kalarak – LLM) → Yanıtı Döndürme
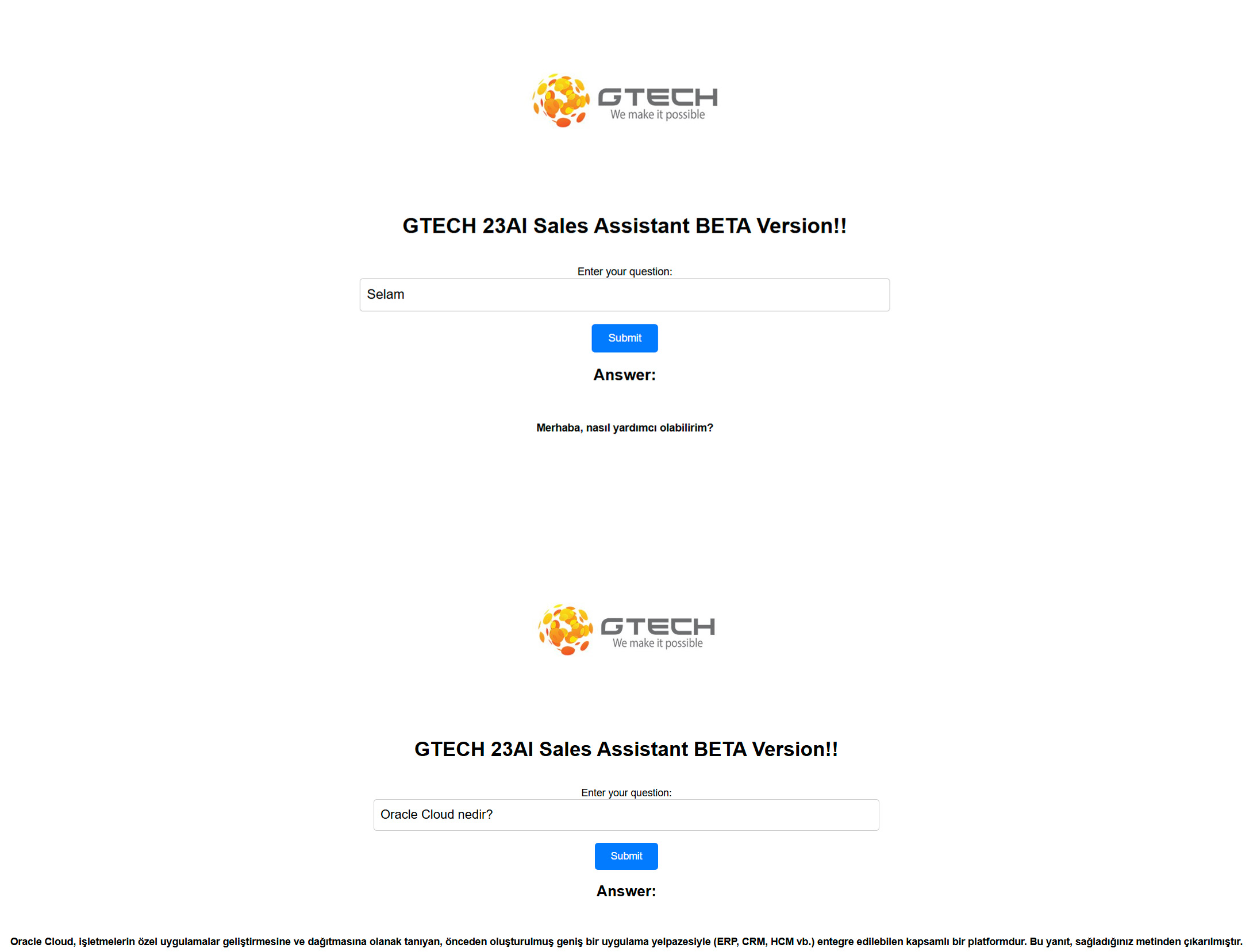
İlk Görsel: Sistemin normal bir sohbet botu gibi gündelik yanıtlar verebildiğini gösterir.
İkinci Görsel: Yüklediğimiz belgeden beslenen RAG ile oluşturulmuş bir yanıtı gösterir.
Sonuç
Bu RAG tabanlı sistem, bilgi çekme ve üretken yapay zekanın güçlü bir birleşimidir. Cohere’nin gömü ve yeniden sıralama modellerini, Oracle 23AI’nin vektör veri türü ve Flask ile entegre ederek, kullanıcı sorgularına harici bilgi kaynaklarına dayalı bağlamsal olarak doğru yanıtlar sağlar.
Cohere’nin LLM’i gibi üretken modellerle bilgi çekme yaklaşımlarını birleştirerek, geniş bir soru yelpazesini ele alır ve kullanıcıların veritabanında bulunan bilgilere dayalı en ilgili ve doğru yanıtları almasını sağlar.
Toygun Toğay, Sistem ve Veritabanı Yönetimi Danışmanı