Yapay Sinir Ağları ve Uygulamaları – 2

GTech Büyük Veri ve İleri Analitik uzman ekibimizin hazırladığı Yapay Sinir Ağları yazı serimizin birinci bölümünde, yapay sinir ağlarında hazır kütüphanelerin model oluşumunda kullanıldığından ve yapılacak adımlardan bahsetmiştik. Bu yazımızda ise; yüksek seviyeli olan Keras kütüphanesi ile Yapay Sinir Ağı modelinin nasıl oluşturulduğuna değineceğiz.
Keras ile Yapay Sinir Ağı’nın Oluşturulması
Yaptığımız çalışmada kullanılan veriler Ulusal Diyabet ve Sindirim ve Böbrek Hastalıkları Enstitüsü’ne (National Institute of Diabetes and Digestive and Kidney Diseases) ait “pima-indians-diabetes” veri setinden alınmıştır. Çıktı verileri ile beraber 9 öz niteliğe ve 768 kayıda sahip bu veri seti, Pima Indians’ lerin diyabet olup olmadığını gösteren tıbbi kayıtları içermektedir. Oluşturulacak model ile hastanın diyabetli ya da diyabetsiz olduğuna dair tahminler yapılacaktır.
Modelin oluşturulması için takip edilen adımlar:
Bir model veya ağ oluşturulurken kullanılacak veri seti, eğitim ve test için ayrıştırılmaktadır. Manuel olarak veri ayrıştırma işlemi yapılabilse de python’da scikit-learn kütüphanesine ait train_test_split metoduyla kolaylıkla yapılabilmektedir. Ayrıca veri seti doğrudan numpy.loadtxt fonksiyonuyla ndarray olarak okunabilmektedir. Python verileri farklı fonksiyonlar ile de okuyabilmektedir.
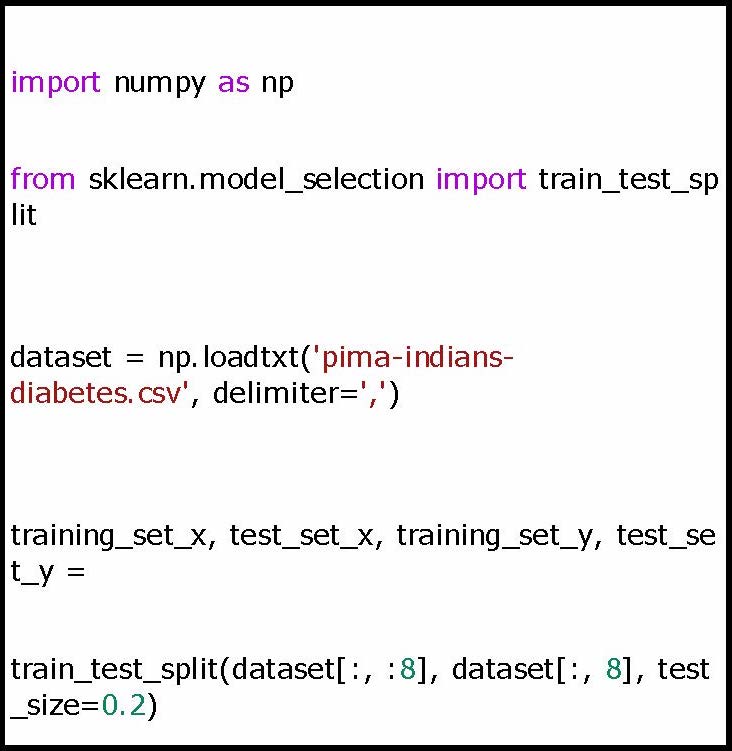
Yukarıda yapılan işlemde veri setinin ilk 8 özniteliği girdi bilgilerini, 9. öznitelik ise çıktı bilgilerini temsil etmektedir. Yapay sinir ağlarında genellikle veri setinin yüzde 70’ i veya yüzde 80’ i eğitim için ayrılmaktadır. Bu çalışmada yüzde 80’ i kullanılmaktadır. Bu parametre değeri veri setine göre değiştirilebilmektedir.
Yapay sinir ağları bir sınıf nesnesi olarak temsil edilir ve bunun için daha çok sıralı katmanlar oluşturan “Sequential” isimli sınıf veya model kullanılmaktadır. Sequential ile obje ya da nesne oluşturulmaktadır;

Oluşturulan modele katman eklemek için Sequential sınıfının “add” metodu kullanılmaktadır. Fakat öncellikle ekleyeceğimiz katmanları bir sınıfla temsil etmememiz gerekmektedir. Keras’ta katmanları temsil eden “Dense” en çok kullanılan sınıflardan biridir. Dense ile katmanlar arasında nöron ya da düğümlerin geçişlerini sağlar. Bir başka deyişle, bir katmandan aldığı nöronları bir sonraki katmana girdi olarak bağlanmasını sağlar.
Dense farklı birçok parametreleri ile model başlangıcına imkan verir. Aşağıda ele alınan parametreler katmanlar için temel olarak olması gereken parametrelerdir;

Model bir girdi katmanı, iki hidden katman ve bir çıktı katmanından oluşmaktadır. Kullanılan nöron sayıları ve hidden katman sayıları verinin yapısına ve modelin başarısına göre değiştirilebilmektedir.
Dense metodunda 20 ile belirtilen “units” parametresi ile 20 nöronlu hidden katmanlar oluşturulmuştur.
“Input_dim” parametresi, girdi verisinin boyutunu belirtmektedir. Kaynaklarda Dense’ in parametrelerinde genellikle input_dim parametresi bulunmamaktadır. Bu parametre özel bir parametre olup sadece girdi katmanı için kullanılan bir parametredir.
“activation” parametresi, ağda kullanılacak aktivasyon fonksiyonunu temsil etmektedir. Farklı özelliklere sahip bir çok aktivasyon fonksiyonu vardır. Eğitim başarısına ve veri setine göre farklı fonksiyonlar kullanılabilmektedir. Bu çalışmada örnek olarak “relu” ve “sigmoid” fonksiyonları kullanılmaktadır.
Ağın konfigürasyonu veya derlenmesi için Sequential sınıfının “compile” metodu kullanılmaktadır. Bu metod farklı parametreler alarak eğitim ve performansın gözlenebilmesi için çeşitli fonksiyonlar kullanılmasını sağlamaktadır. Compile metodu üç ana parametreye sahiptir ve bunların dışında da farklı parametreleri bulunmaktadır.
Örnek olarak verilen parametre değerleri en çok kullanılan metrikleri temsil etmektedir;

“optimizer” parametresi, w değerlerinin iyileştirilmesi için kullanılan optimizasyon algoritmalarının kullanılmasını sağlamaktadır. Kullanılan “adam” (Adaptive Moment Estimation) algoritması, her bir parametre için gerçek zamanlı olarak öğrenme oranını günceller.
“loss” parametresi, her eğitimden sonra elde edilen değerler ile gerçek değerler arasındaki hata farkının hesaplanmasıdır. Kullanılan “binary_crossentropy” algoritması, ikil çıktıları olan verilere sahip modeler için kullanılmaktadır. Bu çalışmada da hastanın diyabetli-diyabetsiz durumu ele alındığı için modele en uygun bu yöntem olarak görülmüştür.
“metrics” parametresi, eğitim aşamasında her epoch sonrasında sonuçları değerlendirmek için bir sınanma işlemi yapmaktadır. Kullanılan “accuracy”, modelin başarısını inceleyebilmek için kullanılan yaygın bir metriktir.
Yukarıda ki adımlardan sonra ağın eğitim aşaması Sequantial sınıfının fit metoduyla yapılmaktadır. Fit metodu için aşağıda ele alınan parametreler eğitimde kullanılması gerekli görülen temel parametreleri temsil eder ve bunların dışında da farklı parametrelere de sahiptir;

Kullanılan ilk iki parametre eğitim için kullanılan veri setinde ki girdi ve çıktı verilerini temsil etmektedir.
“batch_size” parametresi; eğitim veya test sırasında girdi bilgilerinin tek tek değil bir grup halinde eğitime sokulmasını sağlamaktadır. Verilen değerler ağın başarısına göre değiştirilebilmektedir.
“epochs” parametresi; veri setinin modele kaç kez gireceğini belirtmek için kullanılmaktadır. Verilen değerler ağın başarısına göre değiştirilebilmektedir. Değerin çok fazla verilmesi bazı durumlarda olumsuzluklara yol açabilmektedir. Yapılan işlemin süresini arttırmasına ya da bir noktadan sonra verdiği başarı oranları gerçeği yansıtmayarak, öğrenimi ezbere dönüştürebilmektedir.
Oluşturulan modelin ya da ağın test edilmesi Sequential sınıfının evaluate metoduyla yapılmaktadır. Evaluate metodu için aşağıda ele alınan parametreler test için ayrılmış girdi ve çıktı verilerini temsil etmektedir ve bunların dışında da farklı parametrelere sahiptir;

Alternatif olarak aşağıdaki gibi de kullanılabilmektedir;

Evaluate metodu, model başarısını anlamak için incelediğimiz değerlendirme metriklerini bize sağlamaktadır. Bu listenin ilk elemanı loss ikinci elemanı ise accuary vermektedir.
Ağ eğitim ve test işlemlerinden geçtikten sonra Sequential sınıfının “predict” metoduyla modelin kestirimini yapabilmektedir. Modelin ya da problemin amacına göre bir koşul belirlenmektedir.
Modelin daha önce görmediği bir veri seti üzerinde model predict edilebilmektedir. Yapılan modele göre predict işlemleri farklılıklar göstermektedir.

Burada yapılan işlem 0.5 değerinde genel bir eşik değeri verilerek hastanın durumunu teşhiş edilmesi istenmektedir. Bunun nedeni sigmoid fonksiyonun 0 ila 1 arasında değer almasından dolayı tipik bir eşik değer üzerinden sonuçlar gözlemlenmiştir.
Adım adım yapılan modelin tamamı;

Ağ Çıktısı ve Sonuç
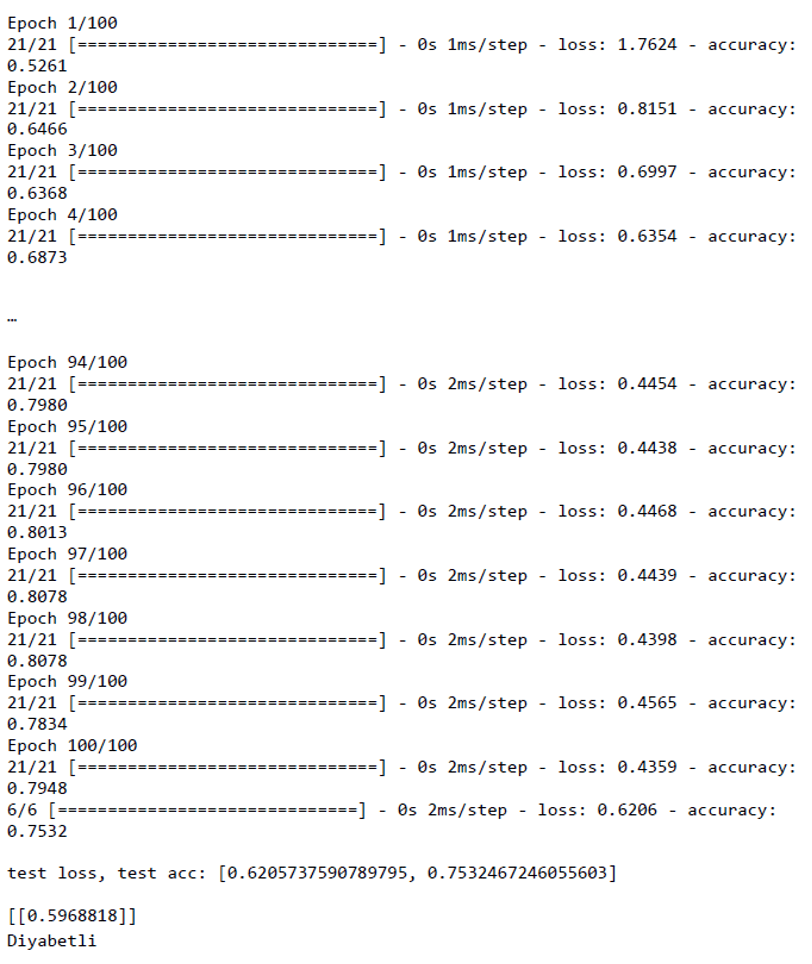
Model bir girdi katmanı, iki hidden katman ve bir çıktı katmanı olmak üzere toplam 4 katmandan oluşmaktadır. Kullanılan nöron sayıları ve hidden katman sayıları veri setine ve modelin başarısına göre değiştirilebilmektedir. Ağın başarısı 97. Epoch’ da % 80 civarlarına geldiği görülmektedir.
Sonuç:
Farklı framework’ lere sahip Yapay Zeka dünyası kullanım kolaylığı ile yapılan geliştirmeleri ve araştırmaları literatürde artırmaktadır. Gelişen teknoloji ile günümüz dünyasında artık zamanı verimli kullanmak önem taşımaktadır. Dolayısıyla Yapay Zeka dünyasında da bu framework’ ler araştırmacılara veya kullanıcılara hız kazandırmakta ve daha çok gelişmeyi sağlamaktadır. Yapay sinir ağları, işleviyle sağladığı kolaylığın yanı sıra, kullanabilirliliği de araştırmacılara ya da kullanıcılara kolaylık sağlamaktadır. Dolayısıyla bu çalışmada yüksek seviyeli olan Keras kütüphanesi, bir çok kod satırı yerine kullanılarak aslında aynı işlemleri kendi fonksiyonları yerine kısa sürede yapabilmemizi sağlamıştır.
GTech Büyük Veri ve İleri Analitik uzmanı Kulilik Süer’in “Yapay Sinir Ağları ve Uygulamaları” yazı serimizde, farklı algoritmalar ve farklı veri setleri ile modeller oluşturmaya devam edeceğiz. Çalışmalarımız hakkında detaylı bilgi almak için bize ulaşın.
Kulilik Süer
GTech Büyük Veri ve Analitik Danışmanı